InputStream中read()与read(byte[] b)
本文共 6860 字,大约阅读时间需要 22 分钟。
原文:  InputStreamTest1.java
InputStreamTest1.java  如果将while循环中的 (char)去掉,即改成:
如果将while循环中的 (char)去掉,即改成:  InputStreamTest2.java
InputStreamTest2.java 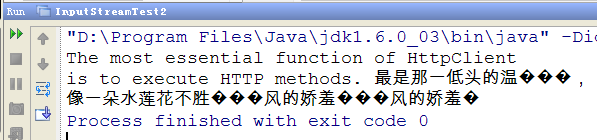 遗憾的是,还是有乱码,解决办法可以参见下面教程 修改后的代码:
遗憾的是,还是有乱码,解决办法可以参见下面教程 修改后的代码:  还是遗憾,没有换行。 解决办法,通过 commons-io-*.jar
还是遗憾,没有换行。 解决办法,通过 commons-io-*.jar 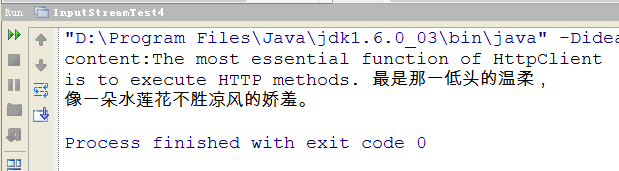
read()与read(byte[] b)这两个方法在抽象类InputStream中前者是作为抽象方法存在的,后者不是,JDK API中是这样描述两者的:
1:read() : 从输入流中读取数据的下一个字节,返回0到255范围内的int字节值。如果因为已经到达流末尾而没有可用的字节,则返回-1。在输入数据可用、检测到流末尾或者抛出异常前,此方法一直阻塞。 2:read(byte[] b) : 从输入流中读取一定数量的字节,并将其存储在缓冲区数组 b 中。以整数形式返回实际读取的字节数。在输入数据可用、检测到文件末尾或者抛出异常前,此方法一直阻塞。如果 b 的长度为 0,则不读取任何字节并返回 0;否则,尝试读取至少一个字节。如果因为流位于文件末尾而没有可用的字节,则返回值 -1;否则,至少读取一个字节并将其存储在 b 中。将读取的第一个字节存储在元素 b[0] 中,下一个存储在 b[1] 中,依次类推。读取的字节数最多等于 b 的长度。设 k 为实际读取的字节数;这些字节将存储在 b[0] 到 b[k-1] 的元素中,不影响 b[k] 到 b[b.length-1] 的元素。 由帮助文档中的解释可知,read()方法每次只能读取一个字节,所以也只能读取由ASCII码范围内的一些字符。这些字符主要用于显示现代英语和其他西欧语言。而对于汉字等unicode中的字符则不能正常读取。只能以乱码的形式显示。 对于read()方法的上述缺点,在read(byte[] b)中则得到了解决,就拿汉字来举例,一个汉字占有两个字节,则可以把参数数组b定义为大小为2的数组即可正常读取汉字了。当然b也可以定义为更大,比如如果b=new byte[4]的话,则每次可以读取两个汉字字符了,但是需要注意的是,如果此处定义b 的大小为3或7等奇数,则对于全是汉字的一篇文档则不能全部正常读写了。 下面用实例来演示一下二者的用法: 实例说明:类InputStreamTest1.java 来演示read()方法的使用。类InputStreamTest2.java来演示read(byte[] b)的使用。两个类的主要任务都是通过文件输入流FileInputStream来读取文本文档xuzhimo.txt中的内容,并且输出到控制台上显示。 先看一下xuzhimo.txt文档的内容InputStreamTest1.java - /**
- * User: liuwentao
- * Time: 12-1-25 上午10:11
- */
- public class InputStreamTest1 {
- public static void main(String[] args){
- String path = "D:\\project\\opensouce\\opensouce_demo\\base_java\\classes\\demo\\java\\inputstream\\";
- File file = new File(path + "xuzhimo.txt");
- InputStream inputStream = null;
- int i=0;
- try {
- inputStream = new FileInputStream(file);
- while ((i = inputStream.read())!=-1){
- System.out.print((char)i + "");
- }
- }catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
/** * User: liuwentao * Time: 12-1-25 上午10:11 */public class InputStreamTest1 { public static void main(String[] args){ String path = "D:\\project\\opensouce\\opensouce_demo\\base_java\\classes\\demo\\java\\inputstream\\"; File file = new File(path + "xuzhimo.txt"); InputStream inputStream = null; int i=0; try { inputStream = new FileInputStream(file); while ((i = inputStream.read())!=-1){ System.out.print((char)i + ""); } }catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }} 执行结果: 如果将while循环中的 (char)去掉,即改成: 引用
System.out.print(i + "");
则执行结果: InputStreamTest2.java - /**
- * User: liuwentao
- * Time: 12-1-25 上午10:11
- */
- public class InputStreamTest2 {
- public static void main(String[] args){
- String path = "D:\\project\\opensouce\\opensouce_demo\\base_java\\src\\demo\\java\\inputstream\\";
- File file = new File(path + "xuzhimo.txt");
- InputStream inputStream = null;
- int i=0;
- try {
- inputStream = new FileInputStream(file);
- byte[] bytes = new byte[16];
- while ((i = inputStream.read(bytes))!=-1){
- String str = new String(bytes);
- System.out.print(str);
- }
- }catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
/** * User: liuwentao * Time: 12-1-25 上午10:11 */public class InputStreamTest2 { public static void main(String[] args){ String path = "D:\\project\\opensouce\\opensouce_demo\\base_java\\src\\demo\\java\\inputstream\\"; File file = new File(path + "xuzhimo.txt"); InputStream inputStream = null; int i=0; try { inputStream = new FileInputStream(file); byte[] bytes = new byte[16]; while ((i = inputStream.read(bytes))!=-1){ String str = new String(bytes); System.out.print(str); } }catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }} 执行结果: 遗憾的是,还是有乱码,解决办法可以参见下面教程 修改后的代码: - /**
- * User: liuwentao
- * Time: 12-1-25 上午10:11
- */
- public class InputStreamTest3 {
- public static void main(String[] args) {
- String path = "D:\\project\\opensouce\\opensouce_demo\\base_java\\src\\demo\\java\\inputstream\\";
- File file = new File(path + "xuzhimo.txt");
- InputStream inputStream = null;
- String line;
- StringBuffer stringBuffer = new StringBuffer();
- try {
- //InputStream :1)抽象类,2)面向字节形式的I/O操作(8 位字节流) 。
- inputStream = new FileInputStream(file);
- //Reader :1)抽象类,2)面向字符的 I/O操作(16 位的Unicode字符) 。
- Reader reader = new InputStreamReader(inputStream, "UTF-8");
- //增加缓冲功能
- BufferedReader bufferedReader = new BufferedReader(reader);
- while ((line = bufferedReader.readLine()) != null) {
- stringBuffer.append(line);
- }
- if (bufferedReader != null) {
- bufferedReader.close();
- }
- String content = stringBuffer.toString();
- System.out.print(content);
- } catch (FileNotFoundException e) {
- e.printStackTrace();
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
/** * User: liuwentao * Time: 12-1-25 上午10:11 */public class InputStreamTest3 { public static void main(String[] args) { String path = "D:\\project\\opensouce\\opensouce_demo\\base_java\\src\\demo\\java\\inputstream\\"; File file = new File(path + "xuzhimo.txt"); InputStream inputStream = null; String line; StringBuffer stringBuffer = new StringBuffer(); try { //InputStream :1)抽象类,2)面向字节形式的I/O操作(8 位字节流) 。 inputStream = new FileInputStream(file); //Reader :1)抽象类,2)面向字符的 I/O操作(16 位的Unicode字符) 。 Reader reader = new InputStreamReader(inputStream, "UTF-8"); //增加缓冲功能 BufferedReader bufferedReader = new BufferedReader(reader); while ((line = bufferedReader.readLine()) != null) { stringBuffer.append(line); } if (bufferedReader != null) { bufferedReader.close(); } String content = stringBuffer.toString(); System.out.print(content); } catch (FileNotFoundException e) { e.printStackTrace(); } catch (IOException e) { e.printStackTrace(); } }} 执行结果: 还是遗憾,没有换行。 解决办法,通过 commons-io-*.jar - /**
- * User: liuwentao
- * Time: 12-1-25 上午10:11
- */
- public class InputStreamTest4 {
- public static void main(String[] args) {
- String path = "D:\\project\\opensouce\\opensouce_demo\\base_java\\src\\demo\\java\\inputstream\\";
- File file = new File(path + "xuzhimo.txt");
- String content = null;
- try {
- content = FileUtils.readFileToString(file, "utf-8");
- } catch (IOException e) {
- e.printStackTrace();
- }
- System.out.println("content:" + content);
- }
- }
/** * User: liuwentao * Time: 12-1-25 上午10:11 */public class InputStreamTest4 { public static void main(String[] args) { String path = "D:\\project\\opensouce\\opensouce_demo\\base_java\\src\\demo\\java\\inputstream\\"; File file = new File(path + "xuzhimo.txt"); String content = null; try { content = FileUtils.readFileToString(file, "utf-8"); } catch (IOException e) { e.printStackTrace(); } System.out.println("content:" + content); }} 执行结果: 转载地址:http://ygqtx.baihongyu.com/
你可能感兴趣的文章
ES学习笔记之-AvgAggregation的实现过程分析
查看>>
学习python自动化运维笔记文件比较
查看>>
PostgreSQL ODBC问题与探索SQLSpecialColumns
查看>>
Teradata join 优化
查看>>
从命令行及java程序运行MyBatis Generator 1.3.x生成MyBatis3.x代码
查看>>
sklearn API 文档 - 0.18 中文翻译
查看>>
配置404错误页
查看>>
Linux下时间戳的换算方法
查看>>
【08】Effective Java - 异常
查看>>
【01】为什么需要UML
查看>>
oracle基本实用技术
查看>>
Lottie开源动画库
查看>>
FlowVisor入门教程
查看>>
基于RYU应用开发之负载均衡(源码开放)
查看>>
Spring中ref local与ref bean区别
查看>>
android binder
查看>>
python 文件获取绝对路径
查看>>
no version information available
查看>>
如何在WIN7上添加磁盘
查看>>
VMWARE 之 ESXI 主机标准安装
查看>>